
A Crise Silenciosa de Junho de 2026
O relatório devastador da Universidade das Nações Unidas (UNU) cravou o impacto: a infraestrutura de IA consumirá 945 Terawatt-hora até 2030.
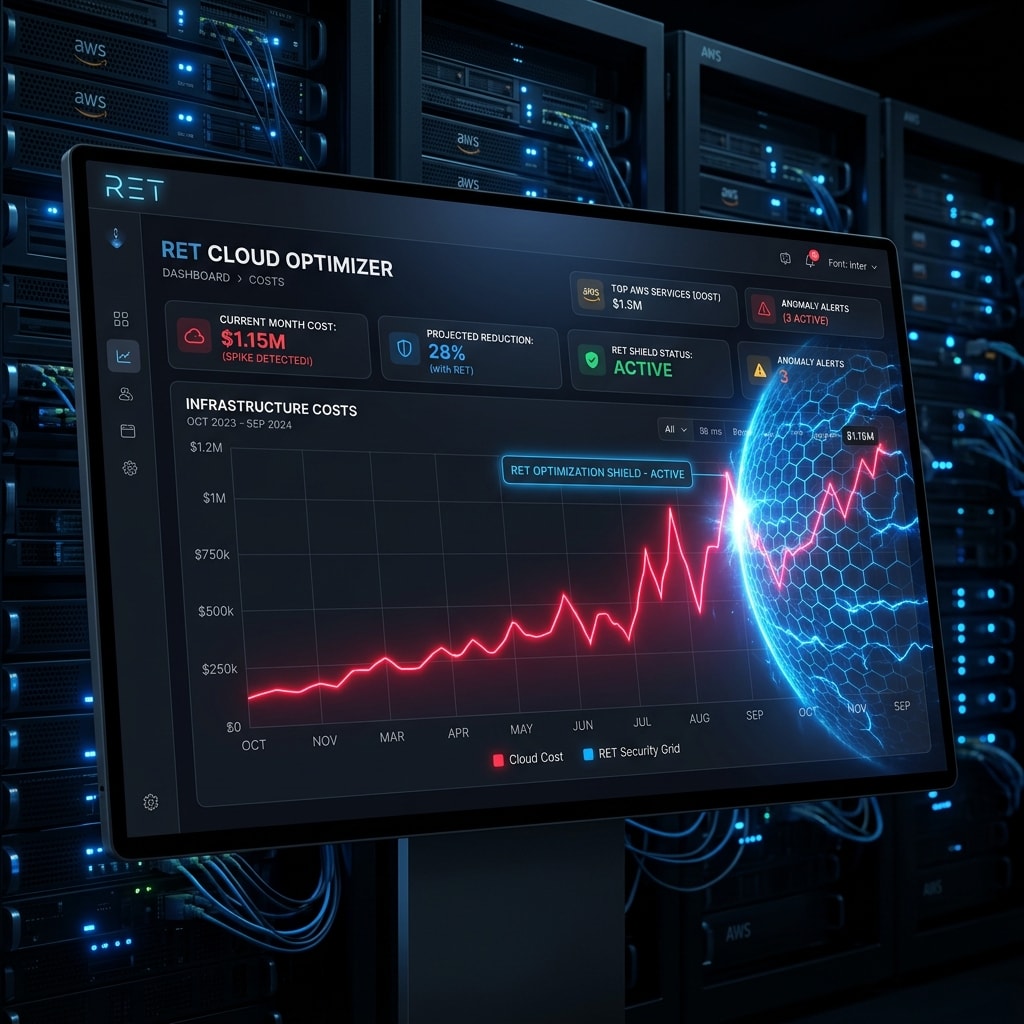
A nível de SaaS corporativo, isso não é apenas uma questão ambiental, é um choque direto no seu P&L (Profit and Loss). Se a sua aplicação bate em rotas Serverless não cacheadas para cada interação de LLM, a sua conta de AWS/GCP vai derreter a sua margem de lucro.
Mitigação Técnica: Arquitetura Defensiva
O seu código não pode mais assumir que o *compute* é infinito e barato.
- Semantic Caching: Respostas de LLM para *queries* similares devem ser cacheadas através de Embeddings Vetoriais. Se dois clientes perguntam variações do mesmo problema, apenas a primeira bate na API da OpenAI.
- Streaming Edge: Processamento em streaming nativo (Edge) diminui o tempo de ocupação da memória em funções serverless.
- Payloads Enxutos: Enviar dados inteiros do banco para o contexto da IA custa tokens caríssimos e memória. O *prompt* deve ser comprimido programaticamente no backend antes do envio.
Código mal otimizado hoje é um vazamento de caixa literal.